As many of us already know, DNS amplification attacks are a big plague for who fights every day for the sake of Internet security and service availability.
Infected hosts are instructed by botnet controllers to send DNS queries to recursive open resolvers, asking them for big zones with spoofed UDP packets containing the victim’s IP address in the source field, so that a small request would generate a big traffic toward the victim.
Small efforts are needed in order to mitigate those attacks – a proper DNS resolvers configuration to avoid open recursion, IP source validation (such as Cisco uRPF) to block source IP spoofing at the access network layer – but they may not be sufficient to immunize a network against annoying issues.
An unpleasant side effect
Even on secure networks an unpleasant side effect may occur: attack reflection against infected hosts, with the consequent backhaul circuit saturation and users’ downstream degradation.
Take, for example, the following not uncommon scenario:
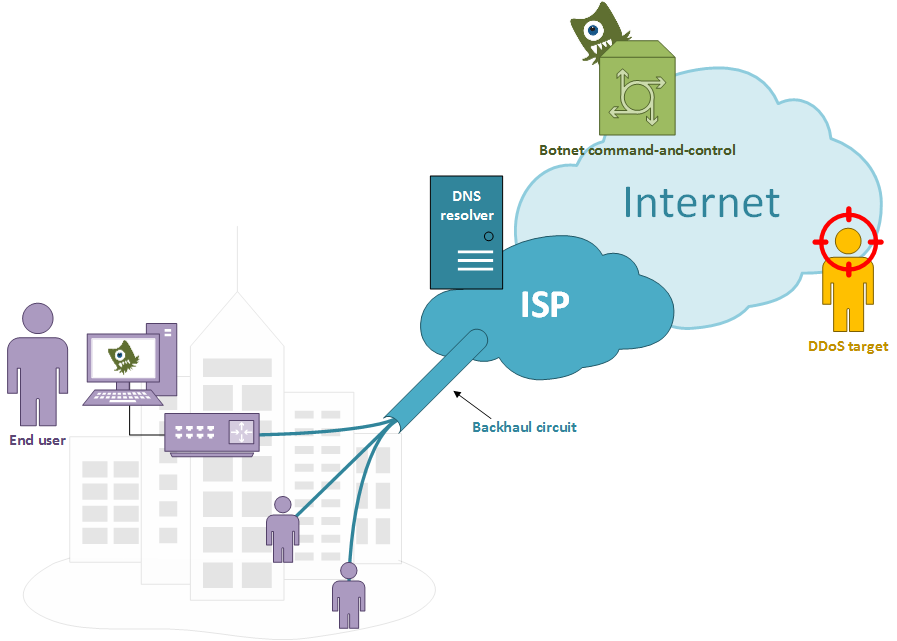
An ISP, running a properly configured DNS resolver, connects many users with a shared backhaul link between its core network and a local metro area; one or more users have infected devices responding to a botnet C&C server who aims to launch a DDoS against a given target.
A well implemented network access layer would stop spoofed packets whose source IP can not be reached through the same link on which they came from. At the same time a properly configured DNS resolver would not let recursive queries to go on by untrusted sources. The problem raises when proper DNS queries came in from trusted users and go to the ISP DNS resolver.
A not-really-failed attack attempt
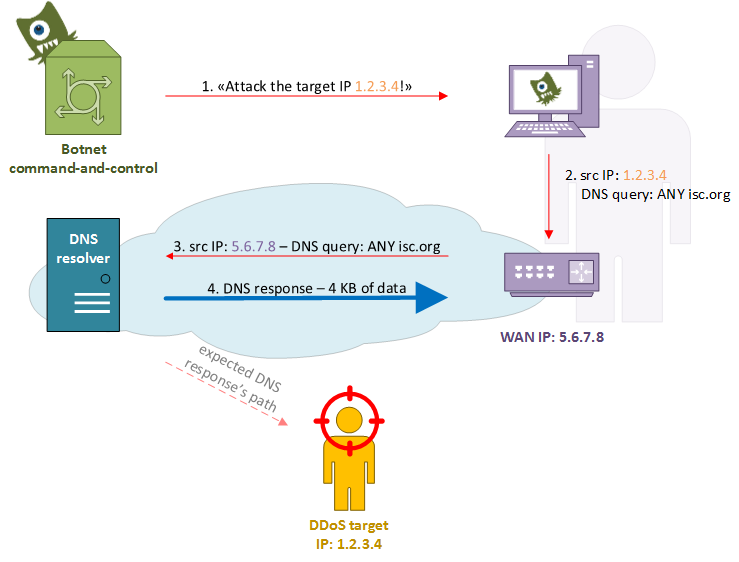
In the above diagram, at step 1, the botnet controller instructs the infected host to start a DNS amplification attack against the victim’s IP address 1.2.3.4. In the step 2 the malicious software tries to send a spoofed packet containing the victim’s address in the source field but something goes wrong: the operating system doesn’t let the malware to forge such a packet and rewrites it using its LAN address, or the router/firewall/CPE changes it with the WAN IP address (NAT). Anyway, at step 3, a proper DNS query comes out the user’s network and heads to the ISP DNS resolver, which in turn sends back a response with the huge DNS zone (step 4).
It’s easy to understand how this behaviour could lead to ISP internal issues regarding the backhaul link saturation and the users experience’s deterioration.
Consequences
A small upstream user’s query (65 bytes for an ANY query on isc.org) produces a big downstream response (~ 4 KB for isc.org zone), with a ~ 60x multiplicative factor. Every infected host may send many and many queries over a long period, even more than 1 query per second for many days, and many compromised hosts may be triggered at the same time by the same botnet controller.
Backhaul links may be rent from incumbent local carriers and may be characterized by an overbooking ratio calculated over the expected usage by customers who share them; high speed links which connect DNS resolvers to the core may overwhelm them when filled by UDP response packets and lead to traffic stagnation because of traffic policing operated by the carrier.
Customers also may report a bad user experience: it’s true, their links are operating at 100% of their capacity, but Facebook is slow and the VoIP is unusable.
A very big headache, even for an ISP with a properly configured network.
Symptoms
The first symptom that can be observed is an abnormal peak in resolvers bandwidth usage:
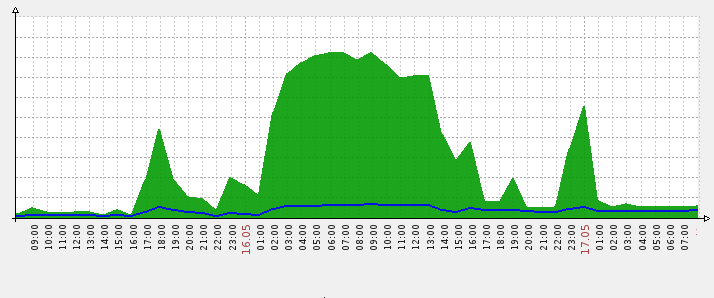
DNS resolver bandwidth usage during an attack attempt – response traffic in green
During an attack attempt the network usage (servers’ upstream) may raise up to hundreds of times higher than average.
NetFlow also may help us to identify this kind of traffic; big response UDP datagrams may be fragmented over the network and they would be shown as port-0 UDP packets in the output of nfdump or similar tools, with an high Bpp (bytes-per-packet) ratio:
Proto Src IP Addr:Port Dst IP Addr:Port Packets Bytes pps bps Bpp Flows
UDP RESOLVER_1:0 -> A.B.1.155:0 78966 106.6 M 48 519300 1350 79
UDP RESOLVER_1:0 -> G.H.4.73:0 35798 48.3 M 25 274100 1350 38
UDP RESOLVER_1:53 -> I.J.5.101:14068 7430 9.3 M 4 46712 1249 187

A 65-bytes request generated a 4157 bytes response in 3 segments – calculated at IP level
Mitigation
Unfortunately, as far as I know, there are still no specific implementations aimed to mitigate those kind of attack.
BIND9 has a generic rate-limit option which prevents a requestor to be told the same answer more than a specific number of times within a one-second interval, but there is no way to apply it only to a subset of responses (like the ones used in DDoS attack, such as ANY to isc.org or ripe.net). DNS RRL (Response Rate Limiting) is focused on authoritative servers, not on recursive ones.
A suitable way would be the use of the iptables recent module on recursive resolvers, but other aspects have to be considered, such as servers load and performances degradation.
A first deep-packet inspection of the incoming DNS requests would filter those DNS queries whose type has been set to ANY, then the recent module would lookup the source IP address on a local list and drop the packet if it violates the predetermined policy. For example, a policy may allow one or two queries with type = ANY every 5 seconds, so that “regular” usage would be allowed while malware initiated traffic would be dropped within few seconds.
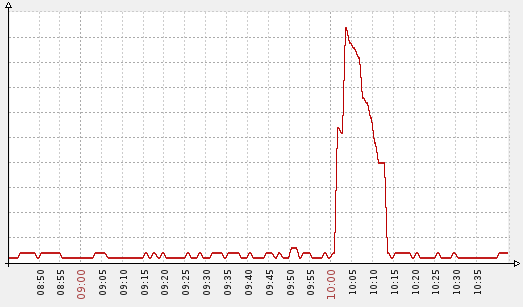
Number of different IP addresses on the recent module’s queue – peak during an attack attemp
References
“Alert (TA13-088A) DNS Amplification Attacks”, US-Cert: http://www.us-cert.gov/ncas/alerts/TA13-088A
“DNS Response Rate Limiting (DNS RRL)”, Paul Vixie, ISC – Vernon Schryver, Rhyolite: http://ss.vix.su/~vixie/isc-tn-2012-1.txt