This is a simple, quick-and-dirty, copy/paste guide to install a great software, pmacct, on a fresh Ubuntu 14.04.1 LTS (Trusty Tahr) setup. I’ll use this simple setup as the basis for other related posts I plan to publish soon.
pmacct
Tl;dr: pmacct is a suite of tools to collect, filter and aggregate IP accounting data, which works with live traffic (libpcap), NetFlow v1/v5/v7/v8/v9, IPFIX, sFlow and ULOG.
A blog post is not enough to show the great features and possibilities that this tool offers, so I really recommend whoever may be interested to read author’s documentation on the official web site.
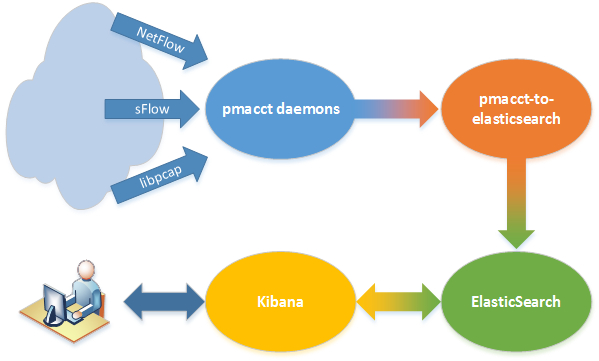
On a next post I plan to show some ideas to deploy pmacct together with ElasticSearch and Kibana, in order to build useful dashboards full of graphs. Add my RSS feed to your reader or follow me on Twitter to stay updated!
EDIT: the Integration of pmacct with ElasticSearch and Kibana post has been published.
Let’s start from a really simple setup here.
Read more …